크롤링!! 3년 만에 하다보니 다 까먹었다....!!! (국비교육 첨 들었을 때 했는데,, 다까먹었넹,, )
다시 학습이 필요해서 급하게 찾아보다가 내가 다시 보려고 정리해본다.
급하게 찾아보니 인프런에 무료 강의가 있었고,
크롤링 방법 중 beautifulsoup4랑 Selenium 쓰는거랑 scrapy쓰는거랑 다양한데,
beautifulsoup4를 써야해서.. 커리큘럼 보고 이를 빠르게 기초 다질 수 있는 강의 찾아서 학습했다.
1. 업무 자동화를 위한 파이썬 pyautogui, beautifulsoup 크롤링 기초
[무료] 업무 자동화를 위한 파이썬 pyautogui, beautifulsoup 크롤링 기초 - 인프런 | 강의
파이썬의 기본을 익히신 분들이 이 강의를 보고 나면 어떤 식으로 파이썬을 활용할 수 있는지 배우게 될 것입니다., - 강의 소개 | 인프런...
www.inflearn.com
import pyautogui로 화면을 띄우거나 해서 직관적으로 보이게 한다. 첨 보는 라이브러리인데 신기했다.
opencv install해서도 진행했는데, 네이버 검색에서 사진을 들고오는 이미지 크롤링은 지금 당장은 아니라서 pass 했지만
유용했다..!!
2. 이것이 진짜 크롤링이다 - 기본편
[무료] 이것이 진짜 크롤링이다 - 기본편 - 인프런 | 강의
크롤링을 처음 배우는 분들을 위해 ① 가장 쉽고 ② 가장 친절하게 설명해 드립니다. 크롤링은 정말로 재미있습니다. 제가 책임지겠습니다. 믿고 따라와 보세요., - 강의 소개 | 인프런...
www.inflearn.com
강의자료로 이해하기 쉽게 풀어서 설명해주셨는데
beautifulsoup에서 html.parse(선생님)과 함께면 수프를 만들 수 있다.
soup = Beautifulsoup(html, 'html.parser') 가 기억이 남는다. ㅋㅋㅋㅋㅋㅋ 귀에 쏙쏙이다. 좋다.
이분도 pyautogui도 설명해주셨고, html 기본 테그를 바탕으로 크롤링이 진행되다 보니
class -> .
id -> #
으로 진행된다는 것도 언급해주셨다.
테그의 별명이 없는 경우도 있는데 이 때는 부모 테그를 바탕으로 진행해서, 테그 없는 경우를 자식 선택자라고 한다.
예를 들어 아래의 경우 제목의 테그는 h4이지만 별명이 없다.
<div class="new_headline">
<h4>제목</h4>
</div>
그래서, .new_headline>h4 이렇게 해서 제목을 가지고 오도록 한다.
뉴스기사 크롤링도 했는데, 한 페이지 제목만 다 크롤링 할 수도 있지만
여러 페이지 자동 크롤링도 할 수도 있으니, 페이지네이션이 이루어 진 url을 보고 클릭해보고 규칙성을 찾는다.
이를 활용해서 반복문을 통해서 자동으로 원하는 페이지 만큼 크롤링이 진행되도록 한다.
import requests
from bs4 import BeautifulSoup
#keyword = pyautogui.prompt("검색어를 입력하세요")
pageNum = 1
for i in range(1, 30, 10):
print(f"{pageNum} 페이지 입니다. ----------------------")
response = requests.get("https://search.naver.com/search.naver?where=news&sm=tab_pge&query=python&sort=0&photo=0&field=0&pd=0&ds=&de=&cluster_rank=23&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so:r,p:all,a:all&start={i}")
html = response.text
soup = BeautifulSoup(html, 'html.parser')
links = soup.select(".news_tit")
for link in links:
title = link.text # 태그 안의 텍스트를 가지고 온다.
# title = link.attrs['title'] # title 속성 값을 가지고 온다. 위와 비교했을 때 어느거 해도 상관 없다.
url = link.attrs['href'] # href 속성값을 가지고 온다.
print(title, '\n',url)
print()
pageNum = pageNum + 1
나는 jupyter notebook으로 했어서, 바로 실행결과를 한줄 한줄 씩 확인할 수 있었다.
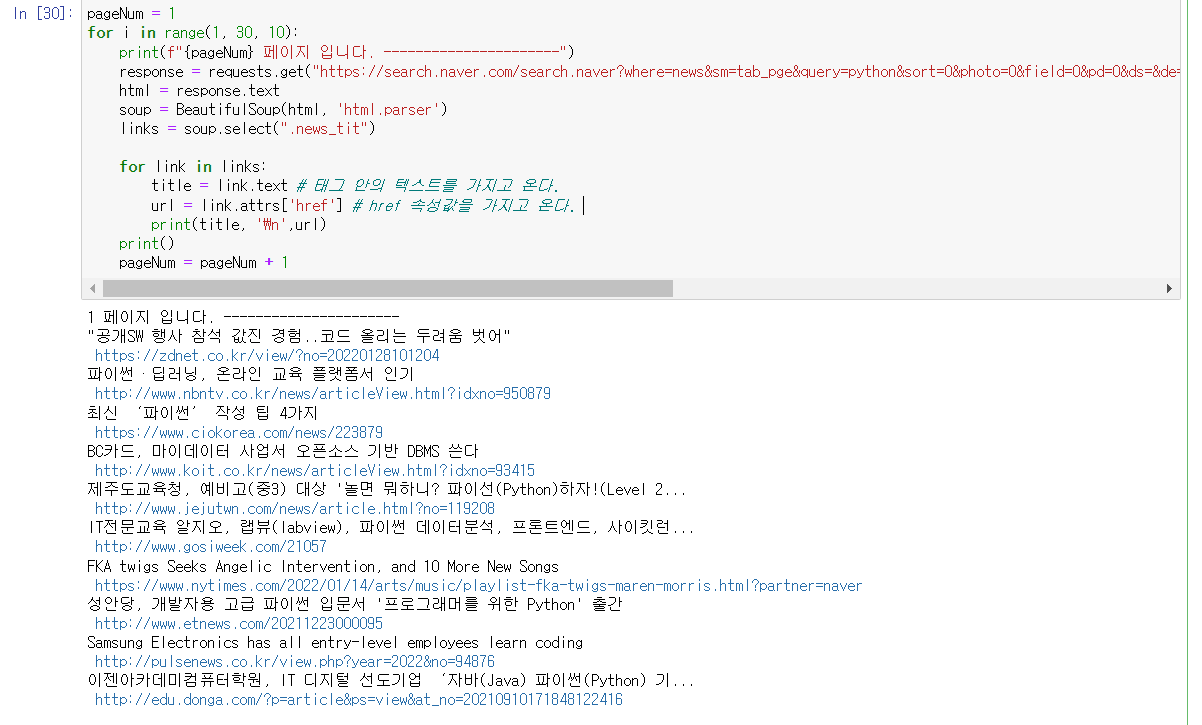
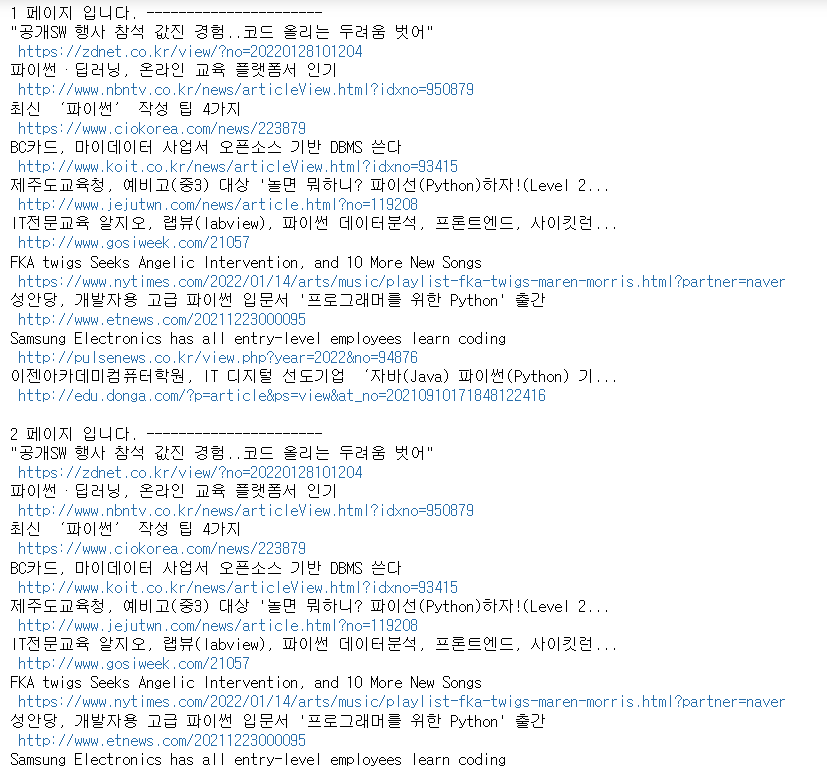
이렇게 확인이 가능하다.
'개발자의 개발개발한 하루 > python' 카테고리의 다른 글
| python iframe 렌더링된 페이지 크롤링 하기 (0) | 2022.02.16 |
|---|---|
| python 3에서 바뀐 것 (출력방식, 문자열 인코딩) (0) | 2022.02.14 |
| 파이썬 크롤링 User-Agent (0) | 2022.02.09 |
| 파이썬 정규표현식 re 사용 (0) | 2022.02.09 |
| 파이썬 크롤링 requests 사용 (0) | 2022.02.08 |




댓글