아주 큰 깨달음을 얻은 날이다.
왜 계속 iframe 크롤링 하는데 왜!! 리스트가 비어서 출력될까..?
도대체 뭐가 문젤까.. 싶어서 찾아보면서 한 예시로 네이버 금융을 테스트 해보았다.
F12를 누르면 개발자 도구가 나오는데, iframe을 눌러서 검색해보면 이렇게 잡혀있고
해당 부분은 src에 적힌 경로대로 다시 렌더링 되어서 페이지가 만들어지기 때문에
attrs로 title까지 얻을 수는 있겠지만 src 이후부터는 가지고 올 수가 없다.
그래서 이걸 어떻게 하면 가지고 올 수 있을까 싶어서 찾아보다가 Selenium을 쓰면 된다는 후기가 많아서
한 번 해봤다. 사실 이 페이지 크롤링 하려고 Selenium까지 쓸 필요는 없는데 워낙 무겁다보니까
근데 테스트 용으로 한 번 해보았다.

추가적으로 해당 src를 우클릭하게 되면 아래와 같이 Open in new tab 이 있다.
말 그대로 해당 소스를 새로운 창에서 열겠다는 의미인데, 클릭해보면
표만 아래처럼 나오게 된다.

해당 창을 iframe으로 심어 두고 src를 통해 삽입한 것으로, 크롤링을 하려면 해당 소스를 우클릭 해서
보여지게 한 화면을 가지고 오도록 해야 한다.

아래의 코드를 주피터로 실행해보면, test_url의 링크의 페이지 전체 소스가 아닌
driver.switch_to.frame("frame_ex1") 즉, iframe 내부 소스로 switch했기에 iframe src를 따라 이동한 것이다.
그래서 soup를 출력해보면 환전 고시 환율 ~ 해서 출력이 됨을 확인할 수 있다.
def testframe():
headers = {
'user-agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}
test_url = "https://finance.naver.com/marketindex"
driver = webdriver.Chrome('./chromedriver.exe')
driver.get(test_url)
driver.switch_to.frame("frame_ex1")
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
print(soup)
driver.switch_to.default_content()
testframe()
주피터 실행 모습은 아래와 같다.
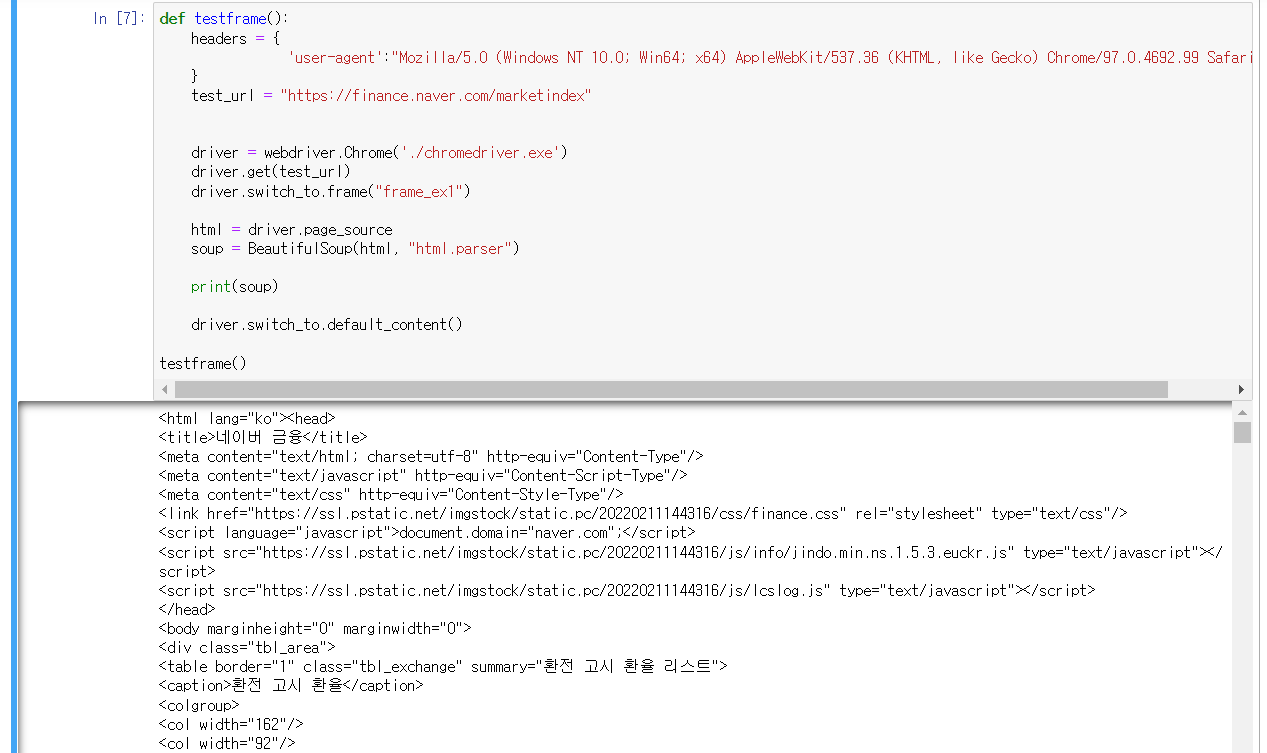
좀더 파싱해서 분리해보면 아래처럼 나올 수 있을 것이다.
import requests
import os, sys
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
def testframe():
headers = {
'user-agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}
test_url = "https://finance.naver.com/marketindex"
driver = webdriver.Chrome('./chromedriver.exe')
driver.get(test_url)
driver.switch_to.frame("frame_ex1")
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
print(soup.find('title').string.strip())
t_table = soup.find_all('tr')
td_ = []
for tab in t_table:
td_.append(tab.find_all('td', limit = 2))
# 앞에 2개는 빈값이라 지우기
i = 0
for tr in td_:
if tr == []:
continue
else:
contry = tr[0].string.strip()
money = tr[1].string.strip()
print(contry, money)
driver.switch_to.default_content()
testframe()
주피터로 실행했을 때 다음과 같이 나온다..!
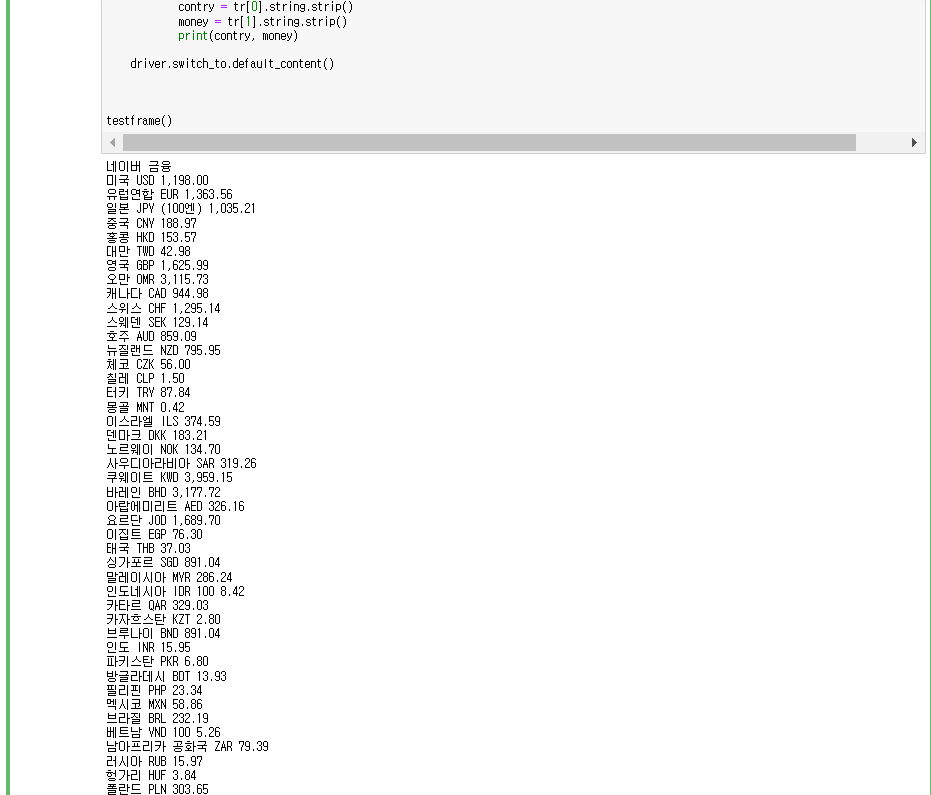
유후.. 암튼 이렇게 처리하면 되는데
매번 실행할 때마다 해당 페이지가 크롬으로 열려서 좀 번거롭긴 했다.
'개발자의 개발개발한 하루 > python' 카테고리의 다른 글
| python logging으로 매일 log 만들기 (backupcount 설정 했는데 안 지워 질 때 해결법) (0) | 2022.03.28 |
|---|---|
| python get_text 와 string 차이 (0) | 2022.03.14 |
| python 3에서 바뀐 것 (출력방식, 문자열 인코딩) (0) | 2022.02.14 |
| 파이썬 크롤링 User-Agent (0) | 2022.02.09 |
| 파이썬 정규표현식 re 사용 (0) | 2022.02.09 |




댓글